1.风险在哪里

1.1信用风险
根据银行业的风险理论,信用风险是指借款人因各种原因未能及时、足额偿还债权人或银行贷款而违约的可能性。
信用风险的风控重点在于,甄别客户违约的原因究竟是还款能力,还是还款意愿问题。如果客户真的由于各方面的原因,暂时不具备还款能力,这是概率问题。即使发生了,处置起来也不会有什么损失。而如果是还款意愿问题,存在较大的资金损失概率。
1.2欺诈风险
在风控中,欺诈风险比信用风险要大得多,所以反欺诈是重中之重。一般来说正常的客户,如果不是刻意骗贷的,只是因为家里出现突发事故、生意出现问题、暂时失业等等原因而导致资金周转不过来而逾期的,这毕竟是少数,而且借款只是逾期,能够还款的概率还是比较高。
消费金融行业绝大多数不良是因为欺诈引起的,如果反欺诈能够比较有效的情况下,信用风险控制在5%以内没有太大问题。
2.主要挑战

消费金融发放的借款都就小额分散的,没有任何抵押和担保的情况。随着消费金融行业的崛起和规模扩大,整个行业面临的欺诈问题越来越严重,一批批的羊毛党和欺诈等黑产团体接踵而来。黑产团队的规模越大,意味着消费金融机构的损失越大。
欺诈风险目前是整体消费金融风控的重点,目前整个行业75%甚至以上的风险都是来自欺诈风险。形式有很多种,如常见的身份伪冒、中介黑产、伪造材料、恶意套现等。欺诈主体一是申请本人或亲戚朋友,二是借用或盗用别人的身份信息进行欺诈。欺诈主体的不同,防范风险的手段和形式也不同。
3.全生命周期管理
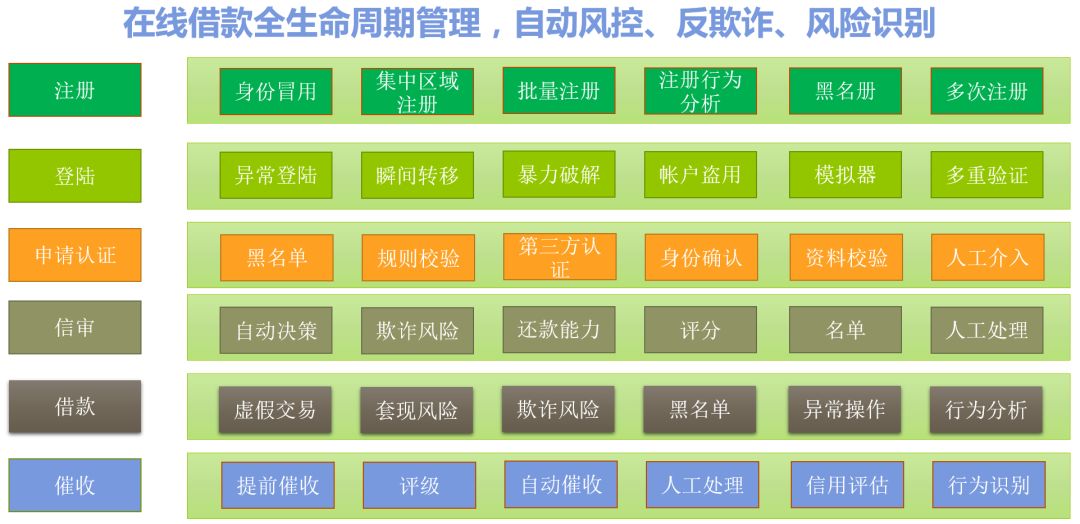
一个完整的风控平台需要包括对借款申请全生命周期进行管理,是一个极为复杂的过程,每一个流程都会影响整体的风控质量。
4.架构实践
4.1业务架构
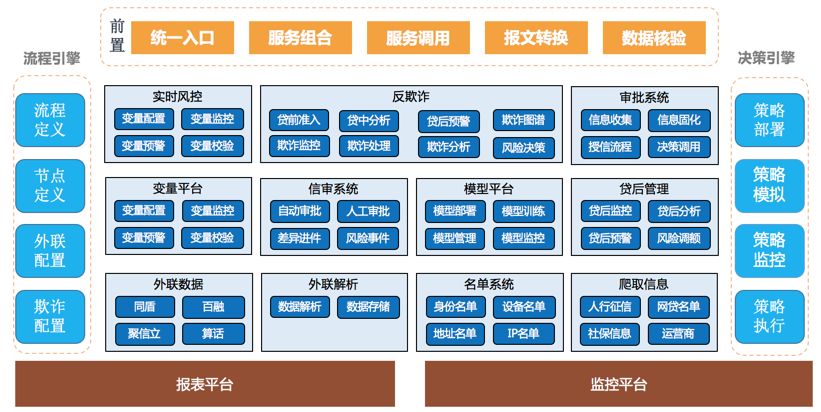
风控平台是相对独立的系统,信审的案件可以从借款端平台推过来,也可以从第三方平台推过来。信审案件到达风控平台后,自动创建工作流,根据风控流程处理各流程环节任务。
•自动决策
风控流程自动处理案件,访问第三方合作伙伴的接口,获取用户黑名单、欺诈数据和多头借贷等数据,查询名单数据,决策引擎输出各环节处理结果。自动决策后出三个结果,自动通过、转人工、拒绝。
•人工信审
根据决策引擎输出的结果进行转人工处理,人工通过初审和复核岗,给出具体信审结果,信审通过的案件给出风险等级和具体额度。
•拒绝
被自动或者人工拒绝的案件通知到用户,建议补充资料、过段时间重新申请或者推荐到第三方机构。
4.2技术架构
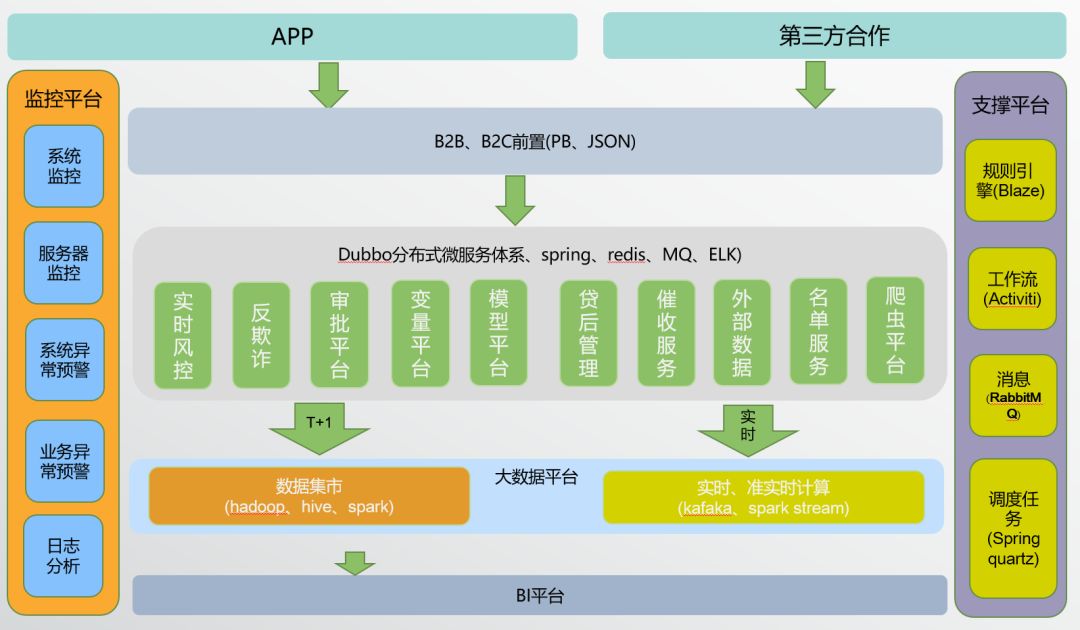
4.2.1分布式、微服务架构
分布式架构目前是互联网行业成熟应用的架构,这里不详细讨论。
微服务架构下,比较成熟的使用Spring Framework,使用MyBatis、Hibernate等数据映射框架。
4.2.2 RPC架构
RPC是分布式架构的核心,解决服务分布和服务解耦问题,目前我们使用的是Dubbo,RPC框架解决序列化、反序列化、网络框架、连接池、收发线程、超时处理、状态机等“业务之外”的重复技术劳动。
4.2.3分布式消息
分布式系统中重要的组件,解决应用耦合,异步消息,流量削锋等问题,是分布式系统不可缺少的中间件。目前在生产环境,使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ等。
4.2.4分布式缓存
高并发环境下,大量的读写请求涌向数据库,磁盘的处理速度与内存显然不在一个量级,从减轻数据库的压力和提高系统响应速度两个角度来考虑,一般都会在数据库之前加一层缓存。由于单台机器的内存资源以及承载能力有限,并且,如果大量使用本地缓存,也会使相同的数据被不同的节点存储多份,对内存资源造成较大的浪费,因此,才催生出了分布式缓存。常用的分布式缓存是Redis。
4.2.5分布式日志
分布式情况下,每个日志分散到各自服务所在机器,日志的收集和分析需要统一处理。日志框架主要这几块内容:
•业务日志埋点
•日志收集处理系统
•日志处理系统
•日志分析系统
ELK(ElasticSearch,Logstash,Kibana)平台可以实现日志收集、日志搜索和日志分析的功能。
4.3反欺诈平台
目前的欺诈团伙已经形成完整的地下产业链,反欺诈平台需要根据平台沉淀的用户数据、环境数据、第三方数据结合生物探针技术采集的本次用户行为数据,建立用户、环境、行为画像以及基于用户、环境、行为的关系网络,通过对业务数据建立多重模型来甄别对异常用户的识别能力和反欺诈能力。
4.3.1数据来源
数据源主要是三个方向:
1.用户申请过程的填写的数据和埋点时采集的行为数据和日志数据。
2.第三方合作数据,如人行征信数据、学历、多头借贷等数据。
3.互联网上的数据,需要靠开发的爬虫平台去抓取。
数据分类主要以下几类:
1.身份信息:姓名、身份证、手机号、卡号、居住地址、学历等。
2.信用信息:收入信息、借款信息、帐户信息、还款和逾期信息。
3.社交信息:通迅录信息、通话记录、QQ和其它平台交互信息。
4.消费信息:银行卡详单、电商网站购买信息等其它信息。
5.行为信息:申请和填写信息、GPS、时间点、地点等信息。
6.第三方:多头信息、黑灰名单、授信信息。
4.3.2反欺诈模型
以上的多方面数据,可以根据对用户行为、语义、关联网络等组成一个巨大的数据关系图谱。利用这些数据建立的模型风控体系对用户的欺诈概率、还款风险等进行强有力的预测和判断。
4.3.2.1社交图谱模型

利用“手机-设备”及“手机-手机(通话)”关系,进行图建模,所有用户及外部已知风险手机号容纳在一张图中,通过图中的风险标记以及图中的异常关系结构。
用户数据量上来的时候,社交关系很容易破亿,这时候就要使用图数据库,相对成熟就是Neo4j,比易用性和稳定性来讲Neo4j比orientdb和arangodb要好很多。
NEO4J数据库,其可提供35亿节点,当前2.5亿多点,其中付费版支持无限节点,费用是6.8万美元/年。
4.3.2.2黑产攻击模型
通过分析收集的高风险人群及中介通话数据,挖掘出一张高风险人群联系密切的关系网,有效识别申请动机不良的客户,发现黑产攻击苗头。
4.3.2.3多头授信模型
通过对客户与各类机构的通信关系,发现一些体现多头风险异常结构,如客户总被一些催收机构联系,同时又在主动拨打其他一些机构的营销电话。
4.3.2.4频次异常分析
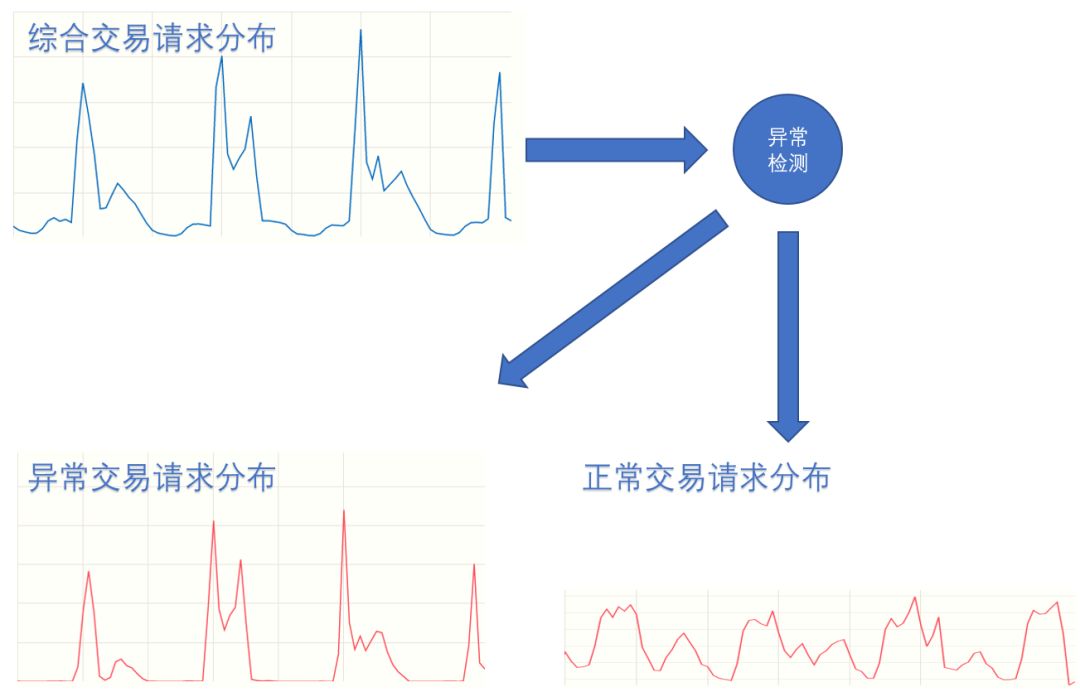
欺诈团伙在发现系统规则漏洞时,往往会在短时间内发起大量欺诈交易,以便在受害者反应过来前尽快变现,例如医美欺诈案,短时间内大量发起虚假的美容贷款请求。
这种交易的频次常常会在时间分布上形成异常的波形,通过ARIMA模型可以很好的预测事件的时间分部特征,贝叶斯框架的生成式模型能够解决不同空间分布维度下细颗粒都的时间分布问题。
通过这两种手段可以将时间和空间分布上存在异常的交易行为与正常的交易行为区分开来。
4.3.2.5欺诈团伙发现
在互联网金融行业,欺诈团伙日益严重并且难以防范。从特点上来看,团伙欺诈有如下几个特点:
•专业性。欺诈团伙通常会根据各平台的风控规则,制定相应的欺诈手段;
•多变性。欺诈团伙的欺诈手法经常变化,让各平台防不胜防;
•爆发性。欺诈团伙一旦发现欺诈的可能性,会在短时间内,利用地下渠道获得的身份信息,大量反复地欺诈;
团伙欺诈的发现是业务反欺诈领域面临的一个重要挑战。目前反团伙欺诈技术思路如下:
•构成网络:将交易,交易信息项(地址,电话,设备id),用户等定义为节点;同属一个交易的节点间形成边;对边根据业务经验或其他规则赋予权重;
•特征提取和信息挖掘:提取网络饱和度,网络直径,关联度,中心度,群聚系数等特征;基于已有的黑名单,利用社区发现等算法得到节点的欺诈相关程度预测;
•加入模型:提取的特征可以作为模型或规则的输入;
•欺诈预警:在无标注数据的情况下,及时发现异常的网络拓扑结构,作为欺诈的早期预警;
4.3.2.6评分模型
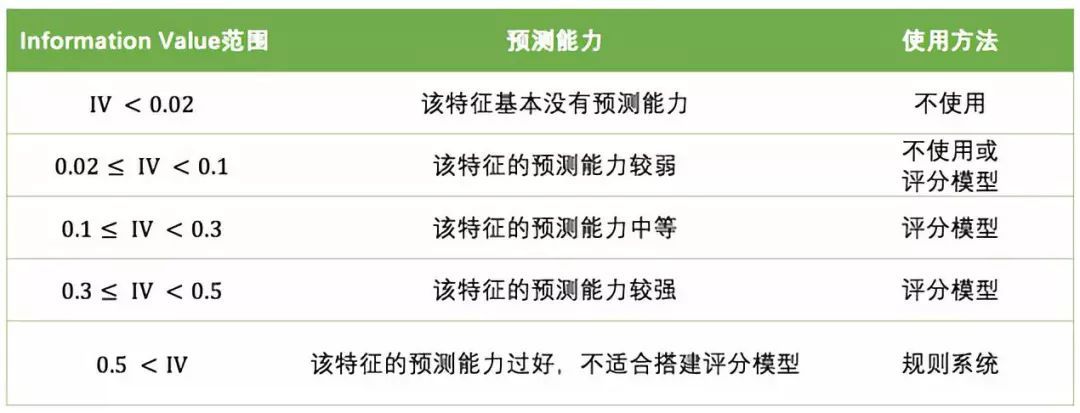
在消费金融反欺诈领域,各种欺诈特征常以规则形式出现,通过一系列的规则的逻辑组合,排除有欺诈嫌疑的进件:
•规则系统优点:可解释性强,可以迅速调整,应对欺诈手段变化;
•规则系统缺点:复杂的规则体系难于维护,难以利用弱特征,对强特征依赖,容易被攻破;
评分模型:评分模型在金融领域应用相当成熟,信用评分模型是最常见的应用。但公司将评分模型应用到反欺诈场景时常常与信用评分混淆,但本质上,二者的预测目标是不同的,反欺诈模型预测的是欺诈的可能性,信用模型预测的是还款的可能性。因此建立独立的反欺诈评分模型很有必要。
反欺诈评分模型有如下优点:
•可以充分利用弱特征;
•对抗性好,模型结构由一系列弱特征决定,提高欺诈者伪装成本;
反欺诈评分模型和反欺诈规则系统有很好的互补性,在风控平台中,同时建立起反欺诈规则系统和评分模型很有必要。
4.4变量平台
反欺诈模型和信用模型两个模型体系里,最基础的需要先加工出风控变量,根据基础信息、关联关系、信用历史、设备信息、社交数据以及消费和交易数据等六大纬度加工出数百、数千或者数万个变量。输出给模型进行计算和决策。
基于实时决策的风控流程需要对数据和大部分变量加工有实时性要求。随着数据量越来越大,传统关系数据无法解决实时和效率的问题,基于Hadoop平台的解决方案成为变量平台的方案。

4.4.1数据来源
•实时日志采集:
业务埋点在流程处理中把风控需要的数据打印到日志中。
Flume从日志采集的数据放入kafka消息队列中。
•实时日志采集:
通过Canal分析mysql的bilog日志,放到kafka中。
4.4.2数据加工
Spark streaming处理时效只能达到准实时,所以变量加工采用Storm方案。Storm可以达到低延迟的响应,在秒级或者毫秒级完成分析、并得到响应,而且体系能够随着数据量的增大而拓展。
5.总结
消费金融行业这两年规模增长比较快,主要是基于在线的小额分散的借款。一定程度上无法有效和及时的识别真正的客户,某些消费场景内面对欺诈团伙和黑产需要建立有效和多种风控手段和模型。
基于大数据的风控和反欺诈模型起步也没有几年,大部分公司都在逐步完善和成熟的过程,基于机器学习的风险模型也都在大量的投入和尝试。需要从大数据上进行挖掘、分析和建模,利用用户身份数据、行为数据、外部数据和黑产数据建立反欺诈平台、规则和欺诈关联网络来提高反欺诈能力和风险识别能力。
